打赏
打赏
「微软文本转语音」Azure Text to Speech 确实效果不错,拥有多种声音和情感风格,能像真人一样朗读出抑扬顿挫的感觉,合成的人声非常逼真。
网友利用免费的在线演示制作出了TTS工具。不过这样是没有收费的稳定(随时可能不能使用)详情看这里
还是喜欢命令行来调用,一个python的工具aspeak正好符合我。
安装 aspeak: pip install –upgrade aspeak
例子: aspeak -t “兄弟,加油啊” -l zh-CN
导入txt并转换为wav: aspeak -f input.txt -l zh-CN -o output.wav
有网友使用了另一种方法:调用“微软的”Edge浏览器中的朗读功能。
https://github.com/LuckyHookin/edge-TTS-record 它居然是用aardio开发的,我居然也会一点点。
这个载入的RecordAudio.dll看起来是一个录音调用。
看起来只是启用了这样一个界面(Edge)
// 使用Edge浏览器
import chrome.edge;
var theApp = chrome.edge.app();
//正式的启动chrome进程
theApp.start("\res\index.html")
win.loopMessage();
res目录下的js才是重点。
看了看它下面的js。被洪水淹没的感觉。
https://blog.csdn.net/qq_41755979/article/details/125725807这里有Edge浏览器阅读API解析。
于是我的代码,运行成功。
<script>
const voices = speechSynthesis.getVoices()
function speakbyvoice(text, voice) {
var utter = new SpeechSynthesisUtterance(text)
for (let v of voices) {
if (v.name.includes(voice)) {
utter.voice = v
break
}
}
speechSynthesis.speak(utter)
return utter
}
speakbyvoice("中国话", "XiaoxiaoNeural")
</script>
不过确实比较生硬,没有在线生成的好。
其实H5是支持Web Speech的https://blog.csdn.net/yb305/article/details/111219007,只是同样生硬。
var utterThis = new window.SpeechSynthesisUtterance('你好,世界!');
window.speechSynthesis.speak(utterThis);
至于API的调用还没试,或许有时间用golang试一下。复制如下:
/*
* postman中模拟成功
* 获取可用语音包选项,等价于speechSynthesis.getVoices()
* http url: https://speech.platform.bing.com/consumer/speech/synthesize/readaloud/voices/list?trustedclienttoken=6A5AA1D4EAFF4E9FB37E23D68491D6F4
* method: GET
*/
{
uri: "https://speech.platform.bing.com/consumer/speech/synthesize/readaloud/voices/list",
query: {
trustedclienttoken: "6A5AA1D4EAFF4E9FB37E23D68491D6F4"
}
method: "GET"
}
/*
* postman中模拟成功
* 发送wss连接,传输文本和语音数据,等价于speechSynthesis.speak(utter)
* wss url: wss://speech.platform.bing.com/consumer/speech/synthesize/readaloud/edge/v1?TrustedClientToken=
* send: 发送两次数据,第一次是需要的音频格式,第二次是ssml标记文本(需要随机生成一个requestid,替换掉guid的分隔符“-”即可)
* receive: 接收到的webm音频字节包含在相同requestid的正文部分,用Path=audio\r\n定位正文索引
* 存在的问题: 1、第一次发送的音频格式文本中,只有在webm-24khz-16bit-mono-opus格式下才能成功连接,其他格式尝试后直接断开;
* 2、第二次发送的ssml文本不支持mstts命名空间的解析,是Auzure语音服务的阉割版,例如不能出现xmlns:mstts="****"、<mstts:express-as/>、<p/>、<s/>等语言标记
*/
{
uri: "https://speech.platform.bing.com/consumer/speech/synthesize/readaloud/voices/list",
query: {
trustedclienttoken: "6A5AA1D4EAFF4E9FB37E23D68491D6F4"
},
sendmessage: {
audioformat: `
X-Timestamp:Mon Jul 11 2022 17:50:42 GMT+0800 (中国标准时间)
Content-Type:application/json; charset=utf-8
Path:speech.config
{"context":{"synthesis":{"audio":{"metadataoptions":{"sentenceBoundaryEnabled":"false","wordBoundaryEnabled":"true"},"outputFormat":"webm-24khz-16bit-mono-opus"}}}}`,
ssml: `
X-RequestId:7e956ecf481439a86eb1beec26b4db5a
Content-Type:application/ssml+xml
X-Timestamp:Mon Jul 11 2022 17:50:42 GMT+0800 (中国标准时间)Z
Path:ssml
<speak version='1.0' xmlns='http://www.w3.org/2001/10/synthesis' xml:lang='en-US'><voice name='Microsoft Server Speech Text to Speech Voice (zh-CN, XiaoxiaoNeural)'><prosody pitch='+0Hz' rate ='+0%' volume='+0%'> hello world</prosody></voice></speak>`
}
}
花了一下午的时间读这个js文件,依然没有啥收获,失败。
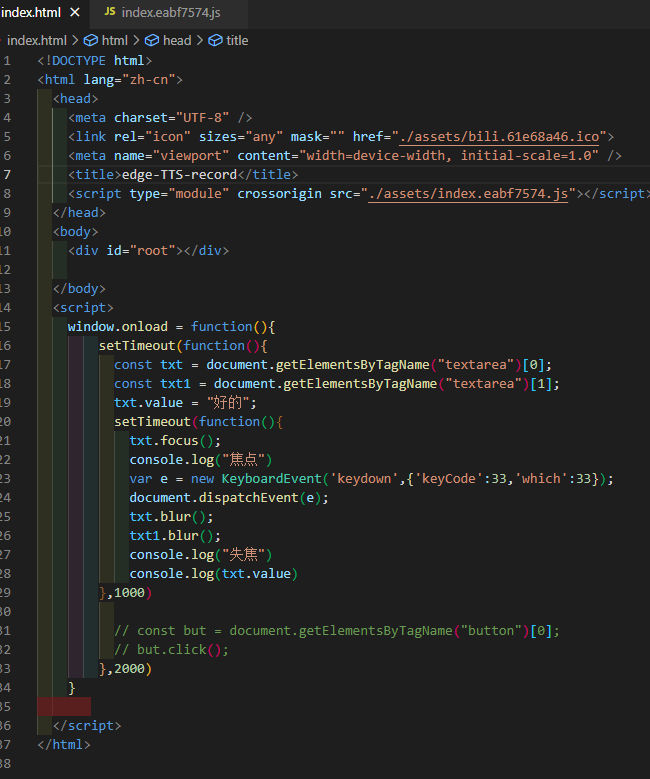
看https://github.com/LuckyHookin/edge-TTS-record其实也只是包了一个js,只要使用Edge浏览器就可以使用它。原本想把它嵌到自己的程序中,完成读新闻的功能,但还是没有学过React,直接赋值给textarea实际没成功。头痛,有机会再试。
截个图,证明来过。